摘要
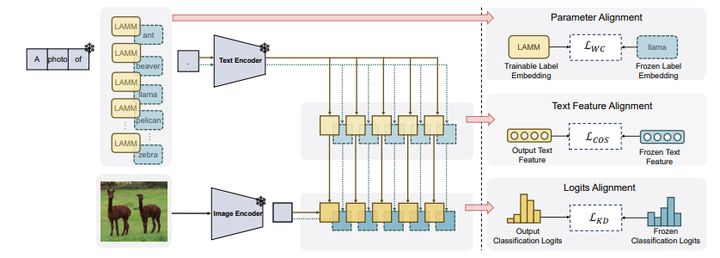
With the success of pre-trained visual-language (VL) models such as CLIP in visual representation tasks, transferring pre-trained models to downstream tasks has become a crucial paradigm. Recently, the prompt tuning paradigm, which draws inspiration from natural language processing (NLP), has made significant progress in VL field. However, preceding methods mainly focus on constructing prompt templates for text and visual inputs, neglecting the gap in class label representations between the VL models and downstream tasks. To address this challenge, we introduce an innovative label alignment method named LAMM, which can dynamically adjust the category embeddings of downstream datasets through end-to-end training. Moreover, to achieve a more appropriate label distribution, we propose a hierarchical loss, encompassing the alignment of the parameter space, feature space, and logits space. We conduct experiments on 11 downstream vision datasets and demonstrate that our method significantly improves the performance of existing multi-modal prompt learning models in few-shot scenarios, exhibiting an average accuracy improvement of 2.31(%) compared to the state-of-the-art methods on 16 shots. Moreover, our methodology exhibits the preeminence in continual learning compared to other prompt tuning methods. Importantly, our method is synergistic with existing prompt tuning methods and can boost the performance on top of them. Our code and dataset will be publicly available at https://github.com/gaojingsheng/LAMM.