DiverSeed: Integrating Active Learning for Target Domain Data Generation in Instruction Tuning
摘要
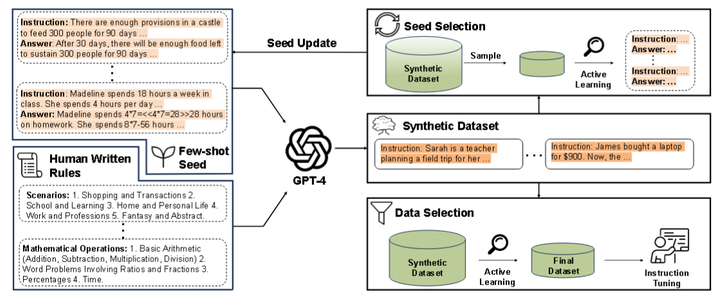
Instruction tuning has demonstrated its potential in aligning large language models (LLMs) to downstream domains; however, this approach heavily relies on extensive, high-quality datasets for fine-tuning through instructions. The construction of a dataset tailored to the target domain becomes crucial, especially when the datasets in downstream domains are scarce. In response, we introduce DiverSeed, a framework based on LLMs for generating datasets specific to target domains. DiverSeed can generate large-scale, diversified datasets based on several seeds from the target domain. Specifically, the pattern of the generated data aligns with that of the reference seed data, thereby reducing the presence of noisy data and elevating the overall quality of the final dataset. Meanwhile, to augment the efficiency of data utilization in the training process and diminish the redundancy in our constructed dataset, we employ seed update and data selection approaches based on active learning strategies. Finally, building upon the DiverSeed framework, we leveraged LLMs to generate two separate high-quality datasets, specifically tailored for mathematical and commonsense reasoning domains. We perform generated data by DiverSeed to finetune different LLMs, and extensive experiments demonstrate that our generated data significantly outperform the gold datasets and other data generation methods. Besides, a comprehensive series of experiments and analyses have established that both the seed update and data selection strategies we proposed effectively enhance the diversity of the generated data, thereby improving the efficacy of model training.